 2022-08-19 16:06:57 来源:商业新知网
2022-08-19 16:06:57 来源:商业新知网
我们可以将大型语言模型(LLMs)理解为小样本学习者,其能够通过很少的例子就能学习新任务,甚至仅通过简单的说明就能学习,其中对模型参数量和训练数据的大小进行扩展是模型拥有泛化能力的关键。LLMs 的这种提升归功于更强大算力和存储能力。直观上,推理能力的提高会带来更好的泛化,从而减少样本的学习,然而目前还不清楚有效的小样本学习在多大程度上需要大量的模型参数知识。
 (资料图片)
(资料图片)
目前为止检索增强模型还没有展示出令人信服的小样本学习能力。论文中,来自 Meta AI Research 等机构的研究者提出小样本学习是否需要模型在其参数中存储大量信息,以及存储是否可以与泛化解耦。他们提出 Atlas,其是检索增强语言模型的一种,拥有很强的小样本学习能力,即使参数量低于目前其它强大的小样本学习模型。
模型采用非参数存储,即使用基于大型外部非静态知识源上的神经检索器去增强参数语言模型。除了存储能力,此类架构在适应性、可解释性和效率方面都存在优势,因此很有吸引力。
论文地址:https://arxiv.org/pdf/2208.03299.pdf
Atlas 检索相关文档是基于 Contriever 双编码器架构的通用密度检索器,检索文件时基于当前上下文检索相关文件。检索到的文档与当前上下文一起交由序列到序列模型处理,该模型使用 Fusion-in-Decoder 架构生成相应的输出。
作者研究了不同技术对训练 Atlas 在一系列下游任务(包括问答和事实检查)上的小样本数据集性能的影响。研究发现联合预训练组件对于小样本性能至关重要,作者评估了许多现有和新颖的预训练任务和方案,Atlas 在小样本和资源丰富的环境中都拥有强大的下游性能。
在只有 11B 个参数的情况下,Atlas 使用 64 个训练示例在 NaturalQuestions(NQ)上实现了 42.4% 准确率,比 540B 参数模型 PaLM( 39.6% ) 高出近 3 个百分点,在全数据集设置中(Full)达到 64.0% 准确率。
Yann LeCun 表示:Atlas 是一个不太大的语言模型(11B 参数),在问答和事实核查方面击败了「大家伙」。Atlas 主要区别在于它可以从语料库中检索事实。
方法概览
Atlas 遵循文本到文本框架。这意味着所有任务的总体框架是:系统以文本查询作为输入,生成文本输出。例如,在问答任务情况下,查询对应于问题,模型需要生成答案。在分类任务情况下,查询对应于文本输入,模型生成类标签,即标签对应的词。图 2 中的 KILT 基准给出了更多下游任务的示例。许多自然语言处理任务需要知识,Atlas 的目标是通过检索增强标准文本到文本模型,因为检索可能对于模型小样本场景下的学习能力至关重要。
架构
Atlas 模型基于两个子模型:检索器和语言模型。当执行任务时,从问答到生成 Wikipedia 文章,模型首先通过检索器从大型文本语料库中检索前 k 个相关文档。然后,这些文档连同查询一起作为输入给到语言模型,生成输出。检索器和语言模型都基于预训练的 transformer 网络,下面对它们做详细介绍。
检索器:Atlas 的检索器模块基于 Contriever,这是一种基于连续密度嵌入的信息检索技术。Contriever 使用双编码器架构,其中查询和文档由 transformer 编码器独立嵌入。平均池化应用于最后一层的输出,以获得每个查询或文档的向量表示。然后通过计算查询和每个文档间的相互嵌入的点积,得到它们的相似度分数。Contriever 模型使用 MoCo 对比损失进行预训练,并且仅使用无监督数据。密度检索器的优点之一是查询和文档编码器都可以在没有文档注释的情况下使用标准技术(例如梯度下降和蒸馏)进行训练。
语言模型:对于语言模型,Atlas 依赖于 T5 序列到序列架构。模型同时也依赖于对序列到序列模型的 Fusion-in-Decoder 修改,并在编码器中独立处理每个文档。之后模型连接对应于不同文档的编码器的输出,并在解码器中对单个序列执行 cross-attention。模型把查询连接到编码器中的每个文档。在语言模型中处理检索到的文档的另一种方法是将查询和所有文档连接起来,并使用这个长序列作为模型的输入。但这种方法可扩展性较差,即它不会随着文档的数量增多而扩展,因为编码器中的自注意力机制会导致 O(n^2)的时间复杂度(这里 n 是文档数量)。
实验结果
作者在 NaturalQuestions 和 TriviaQA 这两个开放域问答基准上评估 Atlas。并且分别使用 64 个样例的小样本数据集和完整的训练集,与之前的工作进行比较,详细对比见下表。
NaturalQuestions 和 TriviaQA 的 64-shot 问答中表现最优。特别是它优于更大的模型 (PaLM) 或需要更多训练计算的模型(Chinchilla)。在使用全量的训练集时,Atlas 也能到最优结果,例如把 NaturalQuestions 的准确率从 55.9% 提高到 60.4%。这个结果是在 Atlas 的默认设置下,使用由 CCNet 和 2021 年 12 月 Wikipedia 语料库组成的索引获得的。
下表展示了在事实核查数据集 FEVER 上的测试结果。
Atlas 在 64-shot 情况下,训练样例采样自全量训练集。Atlas 达到了 64.3% 的准确率。而在 15-shot 的情况下,从每个类中统一采样 5 个样例,与 Gopher 结果比较,Atlas 准确率为 56.2%,比 Gopher 高 5.1 个百分点。在全量训练集上微调 Atlas 模型,达到 78% 的准确率,比 ProoFVer 低 1.5%。ProoFVer 使用专门的架构,用句子级注释训练的检索器,并由维基百科语料库提供与 FEVER 一起发布,而 Atlas 从 CCNet 和 2021 年 12 月的维基百科转储中检索。当给 Atlas 由 FEVER Wikipedia 语料库组成的索引,Atlas 取得了 80.1% 最优水平。
为验证 Atlas 的性能,Atlas 在 KILT 进行了评估,KILT 是由几个不同的知识密集型任务组成的基准。下表展示了测试集的结果。
Atlas 64-shot 在实验中远远超过随机算法,甚至与排行榜上的某些经过微调的模型不相上下。如在 FEVER 上,Atlas 64-shot 仅落后 Sphere、SEAL 和 Re2G 2-2.5 分,而在 zero-shot RE 上的表现优于 Sphere 和 SEAL。在全量数据集上,Atlas 在 3 个数据集的表现与最好的模型相差在 3% 以内,但在其余 5 个数据集中是表现最好的。








有知情人士透露,苹果计划于9月7日召开秋季发布会,发布iPhone 14系列。目前苹果已经通知零售店为9月16日星期五的新产品发布做准备,这意


网易发布Q2财报:游戏全球化提速数字技术焕发传统文化新活力,本季度起网易公司财报中的“在线游戏服务”部分,已更名为“游戏及相关增值服务”
海外创投丨「Gorgias」获3000万美元C轮融资,持续升级电子商务客服工具,融资资金将用于加速其自动化工具的开发,为消费者提供即时客服回复。

海外创投丨「RemediumBio」获230万美元种子轮融资,SherwoodVentures领投,RemediumBio是一家处于临床前阶段的生物技术公司,为多种高度衰弱的


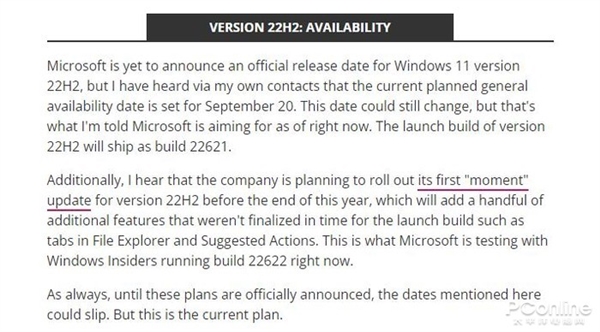
据外媒WindowsCentral获得的消息,微软Windows1122H2(太阳谷2)正式版目前的全面推送日期为9月20日,版本号确认Build22621。此外,消息称微
据外媒WindowsCentral获得的消息,微软Windows1122H2(太阳谷2)正式版目前的全面推送日期为9月20日,版本号确认Build22621。此外,消息称微



融资丨「胜达克半导体」完成亿元级融资,专注于半导体研究,胜达克半导体科技是一家专注于半导体行业后道封装测试领域专用设备的研发、生产和销
零知识证明就像三箭资本的SuZhu和KyleDavies一样,他们出生于上世纪八十年代,但直到最近才成为热门话题。
Adobe通过40多年的努力,打造了一个庞大的商业帝国。
科技部等六部门发文:推动人工智能场景创新。
再加之互联网商业模式的变幻风云诡谲,未来随着技术升级、人们需求变化,很难断言工具出海没戏了。机会小,不代表没有。
第一份省级广电网络、中广电移动分公司与移动省级分公司的《政企业务合作框架协议》签订。





